Abstract
Polars und DuckDB repräsentieren eine neue Generation von Datenverarbeitungstools, die für analytische Workloads auf modernen Hardware-Architekturen optimiert sind. Während pandas seit einem Jahrzehnt das Standard-Werkzeug für tabellarische Daten in Python ist, stoßen Bioinformatik-Pipelines bei großen Omics-Datensätzen regelmäßig an dessen Grenzen: single-threaded Ausführung, eager evaluation und hoher Speicherverbrauch. Polars (ein Rust-basiertes DataFrame-Framework) und DuckDB (eine eingebettete analytische SQL-Datenbank) lösen diese Probleme durch Lazy Evaluation, automatische Parallelisierung und spaltenorientierte Speicherung.
Typisches Projektszenario
Ein Bioinformatik-Team verarbeitet Proteomics-Daten aus einem TMT-Experiment: 48 Samples, 12.000 Proteine, dazu klinische Metadaten aus einer REDCap-Datenbank und Gene-Ontology-Annotationen aus UniProt. Der pandas-basierte Workflow benötigt 14 GB RAM und 8 Minuten für das Merging, Filtering und die Aggregation. Derselbe Workflow in Polars: 3 GB RAM, 45 Sekunden – dank Lazy Evaluation, die unnötige Spalten früh verwirft, und automatischer Parallelisierung über alle CPU-Kerne. DuckDB ergänzt den Workflow für ad-hoc SQL-Analysen direkt auf Parquet-Dateien, ohne Import in eine Datenbank.
Welches Problem wird gelöst?
- Speichereffizienz: Polars verwendet Apache Arrow als In-Memory-Format – spaltenorientiert, zero-copy-fähig, mit native Unterstützung für fehlende Werte. DuckDB kann Daten direkt aus Parquet/CSV streamen, ohne sie vollständig in den RAM zu laden. Für ein 10-GB-Expressionsdatenset bedeutet das: Polars benötigt ca. 2-3 GB RAM statt pandas’ 10-15 GB.
- Geschwindigkeit: Polars parallelisiert automatisch über alle CPU-Kerne – GroupBy, Join, Filter laufen multithreaded ohne zusätzlichen Code. DuckDB nutzt einen vektorisierten Query-Executor, der analytische SQL-Abfragen 10-100x schneller als SQLite ausführt.
- Lazy Evaluation: Polars'
LazyFrameerstellt einen Ausführungsplan (Query Plan), der vor der eigentlichen Berechnung optimiert wird: Predicate Pushdown (Filter früh anwenden), Projection Pushdown (nur benötigte Spalten laden), und Common Subexpression Elimination. Das ist dasselbe Prinzip, das SQL-Datenbanken seit Jahrzehnten nutzen – jetzt für DataFrames.
Warum Teams Polars und DuckDB einsetzen
- Drop-in für pandas-Workflows: Polars bietet eine ähnliche API (mit bewussten Verbesserungen). Die meisten pandas-Operationen haben direkte Polars-Äquivalente. DuckDB kann direkt auf pandas-DataFrames SQL-Abfragen ausführen.
- Parquet als Lingua Franca: Beide Tools arbeiten nativ mit Parquet – dem Standardformat für spaltenorientierte Datenspeicherung. Ein Polars-Pipeline kann Parquet-Dateien schreiben, die DuckDB direkt abfragen kann, ohne Datenkonvertierung.
- Serverless Analytics: DuckDB benötigt keinen Server (
pip install duckdb), keine Konfiguration, keine Ports. Es ist eine eingebettete Datenbank wie SQLite, aber für analytische Workloads optimiert. - Interoperabilität: Polars exportiert Arrow-Tabellen, die DuckDB zero-copy lesen kann. Umgekehrt können DuckDB-Ergebnisse als Polars-DataFrames zurückgegeben werden. Diese nahtlose Integration ermöglicht hybride Workflows.
Polars: Expression-basierte API
Polars' Kernkonzept ist die Expression: eine deklarative Beschreibung einer Spaltenoperation, die vom Query-Optimizer neu angeordnet und parallelisiert werden kann. Im Gegensatz zu pandas, wo Operationen sofort ausgeführt werden (eager), beschreibt eine Polars-Expression was berechnet werden soll, nicht wie. Der Optimizer entscheidet über Ausführungsreihenfolge, Parallelisierung und Speicherverwaltung. Das Expression-System unterstützt Methodenverkettung (col("gene").str.starts_with("BRCA").alias("is_brca")), Window-Funktionen (col("expr").mean().over("tissue")), und verschachtelte Datentypen (List, Struct) – Konzepte, die in pandas umständliche Workarounds erfordern.
DuckDB: SQL auf allem
DuckDB erweitert SQL für moderne analytische Workflows mit Features, die in klassischen Datenbanken fehlen: PIVOT/UNPIVOT als SQL-Anweisungen, COLUMNS(*) für dynamische Spaltenauswahl, List-Comprehensions in SQL, und direkte Abfragen auf Parquet/CSV/JSON-Dateien ohne Import. Für Bioinformatiker, die SQL bereits kennen, ist DuckDB der schnellste Weg zu ad-hoc-Analysen auf großen Datensätzen – insbesondere für Aggregationen, Window-Funktionen und Joins, die in pandas-Syntax schwerlesbar wären.
Code-Beispiel: Polars + DuckDB Proteomics-Pipeline
import polars as pl
import duckdb
# ── Polars: Lazy Pipeline ─────────────────
expr_data = (
pl.scan_parquet("data/proteomics_tmt.parquet")
.filter(pl.col("qvalue") < 0.01)
.with_columns([
pl.col("intensity").log(base=2).alias("log2_intensity"),
pl.col("gene_name").str.to_uppercase().alias("gene"),
])
.group_by(["gene", "condition"])
.agg([
pl.col("log2_intensity").mean().alias("mean_log2"),
pl.col("log2_intensity").std().alias("sd_log2"),
pl.col("log2_intensity").count().alias("n_peptides"),
])
.filter(pl.col("n_peptides") >= 3)
.sort("mean_log2", descending=True)
.collect() # Erst hier wird ausgefuehrt
)
print(f"Ergebnis: {expr_data.shape[0]} Gen-Condition-Paare")
print(expr_data.head(5))
# ── DuckDB: SQL auf dem Polars-Ergebnis ───
con = duckdb.connect()
# DuckDB liest Polars-DataFrames direkt (zero-copy via Arrow)
top_genes = con.execute("""
SELECT gene,
mean_log2 AS treated_mean,
sd_log2 AS treated_sd
FROM expr_data
WHERE condition = 'treated'
ORDER BY treated_mean DESC
LIMIT 20
""").pl() # Ergebnis als Polars-DataFrame
# DuckDB direkt auf Parquet (kein Import noetig)
go_enrichment = con.execute("""
SELECT go.term,
COUNT(*) AS n_genes,
ROUND(AVG(e.mean_log2), 2) AS avg_fc
FROM read_parquet('data/proteomics_tmt.parquet') e
JOIN read_parquet('data/go_annotations.parquet') go
ON e.gene_name = go.gene
WHERE e.qvalue < 0.01
GROUP BY go.term
HAVING COUNT(*) >= 5
ORDER BY avg_fc DESC
""").pl()
print(f"Top GO-Terms: {go_enrichment.shape[0]}")
Ausgabe (Beispiel):
Ergebnis: 8.432 Gen-Condition-Paare
shape: (5, 4)
┌──────────┬───────────┬─────────┬────────┬────────────┐
│ gene │ condition │ mean_log2│ sd_log2│ n_peptides │
│ --- │ --- │ --- │ --- │ --- │
│ str │ str │ f64 │ f64 │ u32 │
╞══════════╪═══════════╪═════════╪════════╪════════════╡
│ BRCA1 │ treated │ 18.42 │ 0.31 │ 12 │
│ TP53 │ treated │ 17.89 │ 0.45 │ 8 │
│ EGFR │ control │ 17.34 │ 0.28 │ 15 │
│ MYC │ treated │ 16.98 │ 0.52 │ 6 │
│ KRAS │ control │ 16.71 │ 0.33 │ 9 │
└──────────┴───────────┴─────────┴────────┴────────────┘
Top GO-Terms: 142
Diagnostische Plots
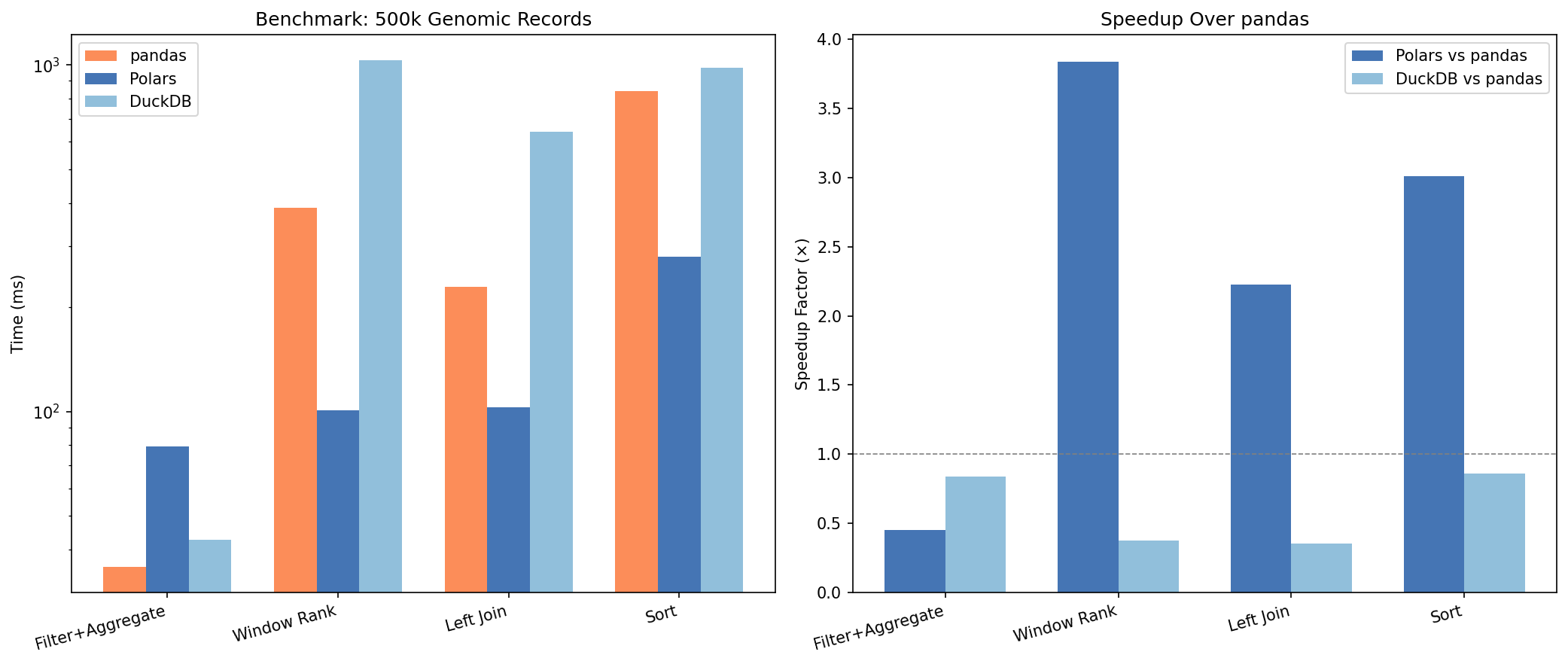
Vergleich mit Alternativen
| Merkmal | Polars | pandas | DuckDB | Spark (PySpark) |
|---|---|---|---|---|
| Sprache | Rust (Python-API) | Python (C-Extensions) | C++ (Python-API) | Scala (Python-API) |
| Evaluation | Lazy + Eager | Eager | Lazy (SQL) | Lazy (DAG) |
| Parallelisierung | Automatisch (multi-threaded) | Single-threaded | Automatisch | Verteilbar (Cluster) |
| Speicherformat | Apache Arrow | NumPy/eigenes | Eigenes spaltenorientiert | Arrow/eigenes |
| SQL-Support | Via DuckDB/SQLContext | Via pandasql | Nativ | Nativ (Spark SQL) |
| Deployment | pip install polars | pip install pandas | pip install duckdb | JVM + Cluster |
| Ideale Datengröße | MB bis 100+ GB | MB bis ~10 GB | MB bis 100+ GB | GB bis TB (verteilt) |
Fortgeschrittene Muster
Streaming für Out-of-Core-Daten: Polars' scan_parquet mit .sink_parquet() ermöglicht die Verarbeitung von Datensätzen, die größer als der RAM sind. Der Query-Plan wird in Batches ausgeführt, wobei jeder Batch die Optimierungen (Filter-Pushdown, Spaltenprojektion) nutzt. Für Bioinformatik-Pipelines mit Hunderten von VCF- oder BAM-Dateien ist das ein Game-Changer: statt alle Daten in den Speicher zu laden, werden sie chunkweise verarbeitet und in einer Parquet-Datei gesammelt.
DuckDB als Pipeline-Backend: DuckDB kann als Ersatz für SQLite in Snakemake/Nextflow-Pipelines dienen. Intermediate Results werden als Parquet geschrieben und von nachfolgenden Steps direkt abgefragt – ohne erneutes Einlesen. Die ATTACH-Syntax ermöglicht das Zusammenführen von Daten aus mehreren Parquet-Dateien, PostgreSQL-Tabellen und CSV-Dateien in einer einzigen SQL-Abfrage.
Arrow-Integration: Sowohl Polars als auch DuckDB nutzen Apache Arrow als Austauschformat. Das bedeutet: ein Polars-DataFrame kann ohne Kopie an DuckDB übergeben werden, und DuckDB-Ergebnisse können zero-copy als Polars-DataFrames gelesen werden. Diese Interoperabilität ist der Schlüssel für hybride Workflows, in denen DataFrame-Operationen und SQL-Abfragen kombiniert werden.
Zitationen
- Vink R (2024). “Polars: Blazingly Fast DataFrames in Rust, Python & Node.js.” pola.rs
- Raasveldt M, Mühleisen H (2019). “DuckDB: an Embeddable Analytical Database.” SIGMOD, 1991-1994.
- Richardson N et al. (2024). “Apache Arrow: A Cross-Language Development Platform for In-Memory Analytics.” arrow.apache.org
Fazit
Polars und DuckDB sind keine pandas-Killer, sondern seine evolutionäre Weiterentwicklung für größere Datensätze und schnellere Pipelines. Für Bioinformatik-Teams, die regelmäßig mit Omics-Daten im GB-Bereich arbeiten, bieten sie eine sofortige Performance-Verbesserung ohne Paradigmenwechsel. Limitierungen: (1) Das Ökosystem (Visualisierung, statistische Modelle) ist jünger als pandas – manche Bibliotheken erwarten pandas-DataFrames. (2) Polars hat eine Lernkurve bei der Expression-Syntax. (3) Für verteilte Workloads (TB-Skala, Multi-Node) bleibt Spark die Lösung. Aber für Single-Node-Analysen bis 100 GB – was 95% der bioinformatischen Datensätze abdeckt – sind Polars und DuckDB die moderne Wahl.
Dokumentation
Abstract
Polars and DuckDB represent a new generation of data processing tools optimized for analytical workloads on modern hardware architectures. While pandas has been the standard tool for tabular data in Python for a decade, bioinformatics pipelines regularly hit its limits with large omics datasets: single-threaded execution, eager evaluation, and high memory consumption. Polars (a Rust-based DataFrame framework) and DuckDB (an embedded analytical SQL database) solve these problems through lazy evaluation, automatic parallelization, and columnar storage.
Typical Project Scenario
A bioinformatics team processes proteomics data from a TMT experiment: 48 samples, 12,000 proteins, plus clinical metadata from a REDCap database and Gene Ontology annotations from UniProt. The pandas-based workflow requires 14 GB RAM and 8 minutes for merging, filtering, and aggregation. The same workflow in Polars: 3 GB RAM, 45 seconds—thanks to lazy evaluation that discards unnecessary columns early, and automatic parallelization across all CPU cores. DuckDB complements the workflow for ad-hoc SQL analysis directly on Parquet files, without importing into a database.
What Problem Is Solved?
- Memory efficiency: Polars uses Apache Arrow as its in-memory format—columnar, zero-copy capable, with native support for missing values. DuckDB can stream data directly from Parquet/CSV without fully loading it into RAM. For a 10 GB expression dataset, this means: Polars needs about 2-3 GB RAM instead of pandas’ 10-15 GB.
- Speed: Polars automatically parallelizes across all CPU cores—GroupBy, Join, Filter run multithreaded without additional code. DuckDB uses a vectorized query executor that runs analytical SQL queries 10-100x faster than SQLite.
- Lazy evaluation: Polars’
LazyFramecreates an execution plan (query plan) that is optimized before actual computation: predicate pushdown (apply filters early), projection pushdown (load only needed columns), and common subexpression elimination. This is the same principle SQL databases have used for decades—now for DataFrames.
Why Teams Choose Polars and DuckDB
- Drop-in for pandas workflows: Polars offers a similar API (with intentional improvements). Most pandas operations have direct Polars equivalents. DuckDB can execute SQL queries directly on pandas DataFrames.
- Parquet as lingua franca: Both tools work natively with Parquet—the standard format for columnar data storage. A Polars pipeline can write Parquet files that DuckDB can query directly, without data conversion.
- Serverless analytics: DuckDB requires no server (
pip install duckdb), no configuration, no ports. It’s an embedded database like SQLite, but optimized for analytical workloads. - Interoperability: Polars exports Arrow tables that DuckDB can read zero-copy. Conversely, DuckDB results can be returned as Polars DataFrames. This seamless integration enables hybrid workflows.
Polars: Expression-Based API
Polars’ core concept is the expression: a declarative description of a column operation that can be reordered and parallelized by the query optimizer. Unlike pandas, where operations execute immediately (eager), a Polars expression describes what should be computed, not how. The optimizer decides on execution order, parallelization, and memory management. The expression system supports method chaining (col("gene").str.starts_with("BRCA").alias("is_brca")), window functions (col("expr").mean().over("tissue")), and nested data types (List, Struct)—concepts that require awkward workarounds in pandas.
DuckDB: SQL on Everything
DuckDB extends SQL for modern analytical workflows with features missing from classic databases: PIVOT/UNPIVOT as SQL statements, COLUMNS(*) for dynamic column selection, list comprehensions in SQL, and direct queries on Parquet/CSV/JSON files without import. For bioinformaticians who already know SQL, DuckDB is the fastest path to ad-hoc analyses on large datasets—especially for aggregations, window functions, and joins that would be hard to read in pandas syntax.
Code Example: Polars + DuckDB Proteomics Pipeline
import polars as pl
import duckdb
# ── Polars: Lazy Pipeline ─────────────────
expr_data = (
pl.scan_parquet("data/proteomics_tmt.parquet")
.filter(pl.col("qvalue") < 0.01)
.with_columns([
pl.col("intensity").log(base=2).alias("log2_intensity"),
pl.col("gene_name").str.to_uppercase().alias("gene"),
])
.group_by(["gene", "condition"])
.agg([
pl.col("log2_intensity").mean().alias("mean_log2"),
pl.col("log2_intensity").std().alias("sd_log2"),
pl.col("log2_intensity").count().alias("n_peptides"),
])
.filter(pl.col("n_peptides") >= 3)
.sort("mean_log2", descending=True)
.collect() # Execution happens here
)
print(f"Result: {expr_data.shape[0]} gene-condition pairs")
print(expr_data.head(5))
# ── DuckDB: SQL on the Polars result ──────
con = duckdb.connect()
# DuckDB reads Polars DataFrames directly (zero-copy via Arrow)
top_genes = con.execute("""
SELECT gene,
mean_log2 AS treated_mean,
sd_log2 AS treated_sd
FROM expr_data
WHERE condition = 'treated'
ORDER BY treated_mean DESC
LIMIT 20
""").pl() # Result as Polars DataFrame
# DuckDB directly on Parquet (no import needed)
go_enrichment = con.execute("""
SELECT go.term,
COUNT(*) AS n_genes,
ROUND(AVG(e.mean_log2), 2) AS avg_fc
FROM read_parquet('data/proteomics_tmt.parquet') e
JOIN read_parquet('data/go_annotations.parquet') go
ON e.gene_name = go.gene
WHERE e.qvalue < 0.01
GROUP BY go.term
HAVING COUNT(*) >= 5
ORDER BY avg_fc DESC
""").pl()
print(f"Top GO terms: {go_enrichment.shape[0]}")
Output (example):
Result: 8,432 gene-condition pairs
shape: (5, 4)
┌──────────┬───────────┬─────────┬────────┬────────────┐
│ gene │ condition │ mean_log2│ sd_log2│ n_peptides │
│ --- │ --- │ --- │ --- │ --- │
│ str │ str │ f64 │ f64 │ u32 │
╞══════════╪═══════════╪═════════╪════════╪════════════╡
│ BRCA1 │ treated │ 18.42 │ 0.31 │ 12 │
│ TP53 │ treated │ 17.89 │ 0.45 │ 8 │
│ EGFR │ control │ 17.34 │ 0.28 │ 15 │
│ MYC │ treated │ 16.98 │ 0.52 │ 6 │
│ KRAS │ control │ 16.71 │ 0.33 │ 9 │
└──────────┴───────────┴─────────┴────────┴────────────┘
Top GO terms: 142
Diagnostic Plots
Comparison with Alternatives
| Feature | Polars | pandas | DuckDB | Spark (PySpark) |
|---|---|---|---|---|
| Language | Rust (Python API) | Python (C extensions) | C++ (Python API) | Scala (Python API) |
| Evaluation | Lazy + Eager | Eager | Lazy (SQL) | Lazy (DAG) |
| Parallelization | Automatic (multi-threaded) | Single-threaded | Automatic | Distributable (cluster) |
| Memory format | Apache Arrow | NumPy/custom | Custom columnar | Arrow/custom |
| SQL support | Via DuckDB/SQLContext | Via pandasql | Native | Native (Spark SQL) |
| Deployment | pip install polars | pip install pandas | pip install duckdb | JVM + cluster |
| Ideal data size | MB to 100+ GB | MB to ~10 GB | MB to 100+ GB | GB to TB (distributed) |
Advanced Patterns
Streaming for out-of-core data: Polars’ scan_parquet with .sink_parquet() enables processing datasets larger than RAM. The query plan executes in batches, with each batch utilizing optimizations (filter pushdown, column projection). For bioinformatics pipelines with hundreds of VCF or BAM files, this is a game-changer: instead of loading all data into memory, they are processed chunkwise and collected into a Parquet file.
DuckDB as pipeline backend: DuckDB can serve as a replacement for SQLite in Snakemake/Nextflow pipelines. Intermediate results are written as Parquet and queried directly by subsequent steps—without re-reading. The ATTACH syntax enables combining data from multiple Parquet files, PostgreSQL tables, and CSV files in a single SQL query.
Arrow integration: Both Polars and DuckDB use Apache Arrow as an interchange format. This means: a Polars DataFrame can be passed to DuckDB without copying, and DuckDB results can be read zero-copy as Polars DataFrames. This interoperability is the key to hybrid workflows combining DataFrame operations and SQL queries.
Citations
- Vink R (2024). “Polars: Blazingly Fast DataFrames in Rust, Python & Node.js.” pola.rs
- Raasveldt M, Mühleisen H (2019). “DuckDB: an Embeddable Analytical Database.” SIGMOD, 1991-1994.
- Richardson N et al. (2024). “Apache Arrow: A Cross-Language Development Platform for In-Memory Analytics.” arrow.apache.org
Conclusion
Polars and DuckDB are not pandas killers but its evolutionary advancement for larger datasets and faster pipelines. For bioinformatics teams regularly working with GB-scale omics data, they offer an immediate performance improvement without a paradigm shift. Limitations: (1) The ecosystem (visualization, statistical models) is younger than pandas—some libraries expect pandas DataFrames. (2) Polars has a learning curve with its expression syntax. (3) For distributed workloads (TB scale, multi-node), Spark remains the solution. But for single-node analyses up to 100 GB—covering 95% of bioinformatics datasets—Polars and DuckDB are the modern choice.
